
HEFLO propose un projet de personnalisation d’API basé sur Node.js qui permet de mettre en œuvre des règles métier avancées, des intégrations et de la manipulation de données pendant l’exécution des processus. En utilisant le projet d’API HEFLO, les développeurs peuvent étendre le comportement de l’automatisation des processus au-delà des configurations BPMN standard. Les personnalisations peuvent être utilisées avec :
- Les éléments BPMN ;
- Les Champs de données externes ;
- Les boutons d’action ;
- Les événements de champs de formulaire tels que l’initialisation, l’ajout, la modification et la suppression ;
- Les déclencheurs de flux d’exécution de processus ;
- La définition dynamique des participants ;
- Les opérations sur les enregistrements personnalisés telles que la création, la mise à jour et la suppression.
La bibliothèque de l’API HEFLO fournit également des fonctions d’aide intégrées qui simplifient l’accès aux données de processus, aux champs d’éléments de travail (work items), aux enregistrements, aux jetons (tokens) et au contexte d’exécution. Une liste complète des déclencheurs, événements et fonctions d’aide disponibles est accessible dans la documentation de l’API HEFLO : Documentation.
Bien que les projets de personnalisation HEFLO offrent la flexibilité d’un environnement de web service complet, ils requièrent également des connaissances en Node.js, la maintenance du projet, l’hébergement de l’infrastructure de déploiement. Pour les organisations qui préfèrent une assistance à l’implémentation, HEFLO propose aussi des services de conseil et d’implémentation.
Note : Une approche alternative pour un projet d’API HEFLO est disponible dans l’article : Aperçu des Intégrations HEFLO : Web Services vs. Personnalisations d’API.
Structure du projet et éléments minimaux
Un projet de personnalisation HEFLO est généralement implémenté sous la forme d’une application Serverless Framework déployée sur AWS Lambda. La structure minimale du projet est :
├── package.json
├── process
├ └── functions.ts
├── serverless.yml
└── tsconfig.json
où chaque fichier a une responsabilité spécifique dans le projet.
package.json
Le fichier package.json définit les dépendances et la configuration du projet. Il contient :
- Les dépendances de packages Node.js ;
- Les dépendances Serverless Framework ;
- Les packages de configuration TypeScript ;
- La dépendance au SDK de l’API HEFLO ;
- Des bibliothèques utilitaires telles qu’Axios, Moment, le parsing CSV et les packages AWS SDK.
Exemple de dépendance : « heflo-api »: « ^1.0.32 »
Le package heflo-api permet d’accéder au contexte d’exécution HEFLO et aux méthodes d’aide utilisées lors de l’automatisation des processus.
serverless.yml
Le fichier serverless.yml définit la manière dont l’application est déployée sur AWS Lambda.
Exemple :
service: projectName
provider:
name: aws
runtime: nodejs16.x
region: sa-east-1
functions:
function01:
handler: process/functions.function01
events:
– http:
path: /function01
method: post
Cette configuration :
- Crée une fonction AWS Lambda ;
- Expose un point de terminaison (endpoint) HTTP ;
- Connecte le point de terminaison à une fonction TypeScript ;
- Permet le déploiement à l’aide du Serverless Framework.
tsconfig.json
Ce fichier définit la configuration du compilateur TypeScript. Les exemples de paramètres incluent :
{
« target »: « ES2020 »,
« module »: « commonjs »,
« strict »: true
}
Le projet utilise TypeScript afin d’améliorer la maintenabilité, la sécurité du typage et les capacités de débogage.
Le fichier functions.ts contient la logique de personnalisation. Chaque fonction exportée peut être utilisée comme :
- Gestionnaire d’événements de formulaire ;
- Action de déclenchement ;
- Point de terminaison (endpoints) d’API ;
- Gestionnaire d’exécution de flux de séquence ;
- Routine d’automatisation personnalisées.
Exemple :
exports.function01 = async (event: any) => {
const body = JSON.parse(event.body);
const context = new HEFLOApi.Events.WorkItem.OnChanged({ body });
const textField = context.WorkItem.Get(« textField »);
// custom business logic here
};
L’élément principal de chaque personnalisation est l’objet de contexte fourni par la bibliothèque de l’API HEFLO. Cet objet donne accès aux éléments suivants :
- Les champs d’éléments de travail (work items) ;
- Les données de processus ;
- Les enregistrements ;
- Les participants ;
- Les informations du jeton (token) actuel ;
- Les méthodes d’exécution du flux de travail.
Installation des dépendances et des prérequis
Avant de lancer le projet, assurez-vous que les outils suivants sont installés :
- Node.js;
- npm;
- Serverless Framework;
- Ngrok.
Pour ce guide, Visual Studio Code sera utilisé comme IDE pour l’édition, les tests et le débogage du projet.
Les étapes suivantes décrivent un processus de configuration simplifié pour préparer l’environnement de développement et créer la structure du projet à partir de zéro.
- Téléchargez et installez Visual Studio Code.
- Téléchargez et installez Node.js depuis le site officiel.
- Après l’installation, validez-la en utilisant une invite de commande ou un terminal :
node -v - Validez également npm :
npm -v - Installez TypeScript.
npm install typescript -g - Validez l’installation :
tsc -v - Installez Serverless Framework.
npm install serverless@3.39.0 -gNote : Consultez la documentation officielle de Serverless Framework pour obtenir la version stable la plus récente. - Validez l’installation :
serverless -v
- Installez ngrok.ngrok est utilisé pendant le développement local pour exposer publiquement l’API locale afin qu’HEFLO puisse accéder aux points de terminaison (endpoints) de personnalisation lors des tests.
- Créez un compte sur le site de ngrok ;
- Téléchargez le fichier exécutable ;
- Extrayez et ouvrez ngrok ;
- Authentifiez l’installation à l’aide de la commande fournie sur le tableau de bord ngrok.Exemple : ngrok config add-authtoken YOUR_TOKEN
Après l’authentification, ngrok est prêt à être utilisé.
Création d’une fonction de personnalisation simple
Après avoir installé tous les prérequis, nous pouvons créer le projet de personnalisation. Tout d’abord, créez le dossier du projet, cela peut être fait directement via VS Code ou via un terminal ; pour cela :
- Ouvrez un terminal et créez le répertoire du projet :
mkdir heflo-customization
cd heflo-customization - Initialisez le projet Node.js ; pour cela, exécutez :
npm init -y - Installez les dépendances du projet.
Pour cet exemple, nous n’installerons que les dépendances minimales nécessaires.npm install \heflo-api \
serverless@3.39.0 \
serverless-offline@8.8.0 \
serverless-plugin-typescript@2.1.2 \
typescript
Note : Le package serverless-plugin-typescript ne prend actuellement en charge que les versions v2 et v3 de Serverless Framework. Pour cette raison, le projet utilise serverless@3.39.0. L’installation de la version la plus récente de Serverless Framework peut entraîner des conflits de dépendances lors de l’installation. Pour éviter tout problème de compatibilité, installez toujours les versions spécifiées dans ce guide.
De plus, installez les dépendances de développement :
npm install –save-dev \
@types/aws-lambda \
serverless-plugin-common-excludes \
serverless-plugin-include-dependencies
- Créez la structure du projet.Une suggestion de structure de projet est présentée ci-dessous.heflo-customization
├── package.json
├── process
├ └── functions.ts
├── serverless.yml└── tsconfig.json
- Créez le fichier tsconfig.json avec le contenu suivant :{
« compilerOptions »: {
« target »: « ES2020 »,
« module »: « commonjs »,
« sourceMap »: true,
« outDir »: « .build »,
« strict »: true,
« rootDir »: « ./ »,
« esModuleInterop »: true
}
}
Cette configuration permet une compilation TypeScript compatible avec Serverless Framework et AWS Lambda.
- Créez le fichier serverless.yml :service: heflo-customization
frameworkVersion: ‘3’
provider:
name: aws
runtime: nodejs16.x
region: sa-east-1
timeout: 30
versionFunctions: false
functions:
function01:
handler: process/functions.function01
events:
– http:
path: /function01
method: post
plugins:
– serverless-offline
– serverless-plugin-typescript
– serverless-plugin-common-excludes
– serverless-plugin-include-dependencies
– serverless-dotenv-plugin
- Créez votre première fonction de personnalisation.Créez le fichier process/functions.ts:import * as HEFLOApi from « heflo-api »;
exports.function01 = async (event: any) => {
try {
const body = JSON.parse(event.body);
const context = new HEFLOApi.Events.WorkItem.OnExecuteSequenceFlow({
body,
});
context.WorkItem.Set(
« textField »,
« Customization executed successfully »
);
return {
statusCode: 200,
body: JSON.stringify(
context.GetModifiedData()
),
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({
message: `Something went wrong: ${error}`,
}),
};
}
};
Cet exemple simple reçoit la charge utile (payload) de l’événement HEFLO, crée le contexte d’exécution HEFLO en fonction du type d’événement, met à jour le champ de processus textField avec le message suivant : « Customization executed successfully », puis renvoie les données modifiées à HEFLO.
Exécution du projet localement
Démarrez le serveur local :
serverless offline

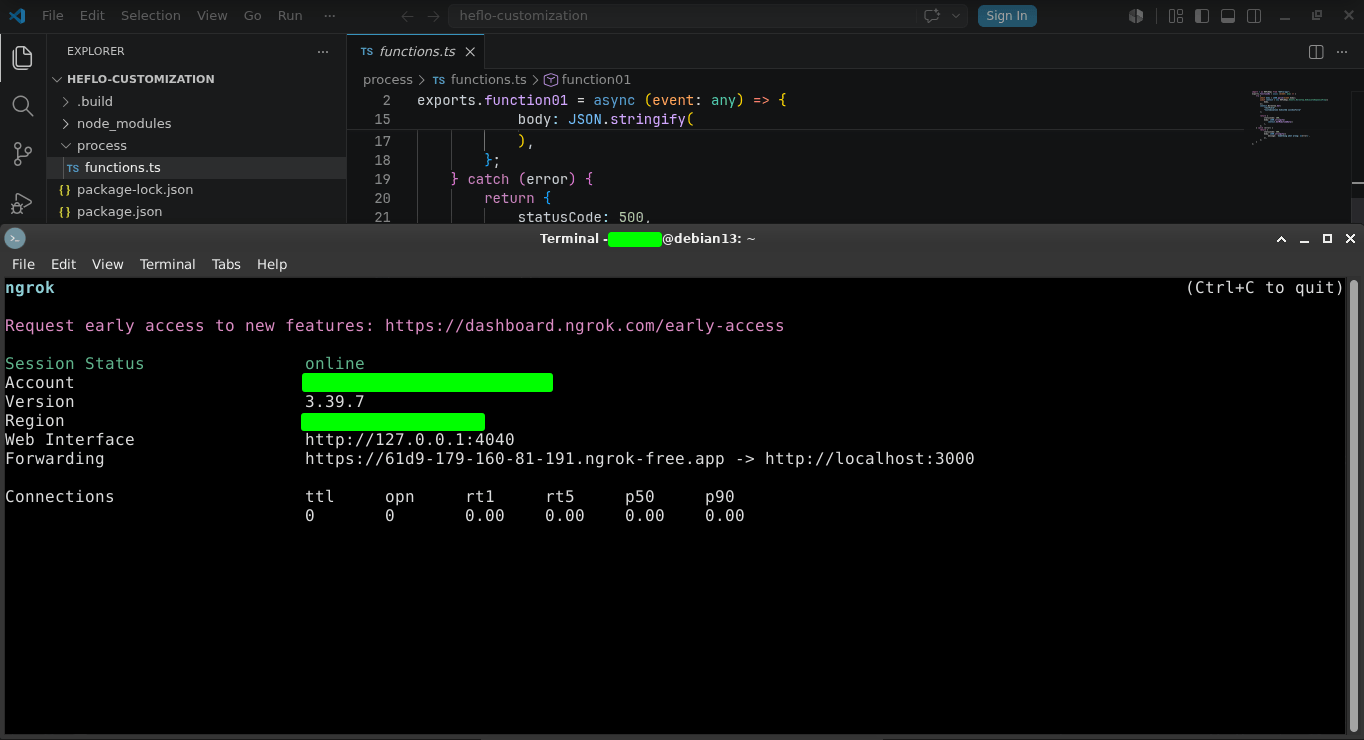
L’API s’exécutera localement sur le port 3000. Ouvrez un autre terminal et exécutez :
ngrok http 3000
ngrok va générer une URL HTTPS publique qui pourra être configurée dans HEFLO pour les phases de test.
Déploiement de la personnalisation
Après avoir testé localement, déployez le projet sur AWS Lambda en utilisant :
serverless deploy
Le processus de déploiement :
- Génère le package de l’application ;
- Télécharge le code sur AWS ;
- Crée les fonctions Lambda ;
- Crée les points de terminaison (endpoints) API Gateway ;
- Renvoie les URL publiques de l’API.
Exemple de sortie :
endpoints:
POST – https://xxxx.execute-api.sa-east-1.amazonaws.com/dev/sampleFunction
Ces points de terminaison peuvent ensuite être utilisés directement dans les configurations d’automatisation de HEFLO.
Utilisation de la personnalisation dans l’automatisation de HEFLO
Après le déploiement, le point de terminaison peut être connecté aux événements d’automatisation des processus au sein de HEFLO.
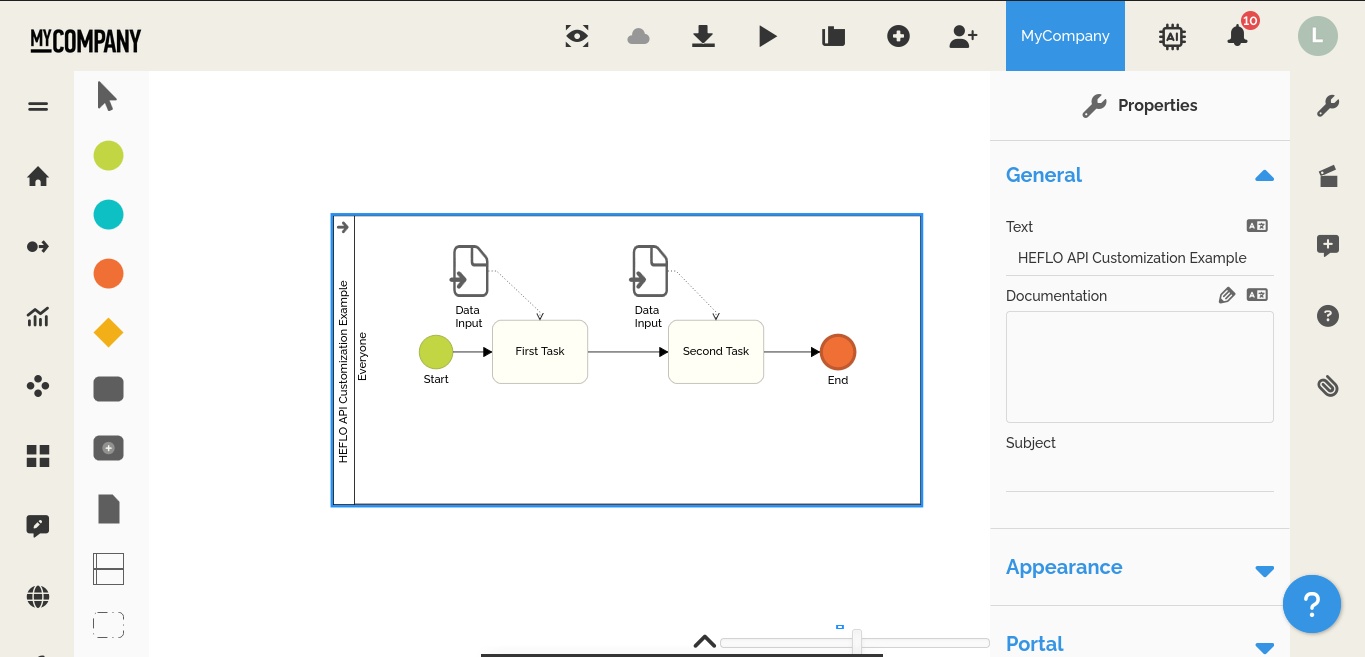
L’étape suivante consiste à créer le processus BPMN et à configurer l’appel du web service ; pour cela, nous utiliserons un diagramme simple à deux tâches afin d’envoyer, de recevoir et d’afficher l’événement sur le champ du formulaire.
- Depuis la page principale de l’environnement HEFLO, accédez à l’éditeur de processus.
- Ouvrez un processus BPMN existant ou créez-en un de toutes pièces.
- Vérifiez que le processus a bien l’option « Processus automatisé » activée.
- Ajoutez l’élément de début, la « Première tâche », la « Seconde tâche » et l’élément de fin comme indiqué sur l’image ci-dessous.
- Sur les deux tâches, ajoutez une entrée de données (formulaire).
- Double-cliquez sur le formulaire pour accéder à la fenêtre de création de formulaire.
- Sur la tâche « Première tâche », créez un champ de texte appelé « Champ de Texte ».
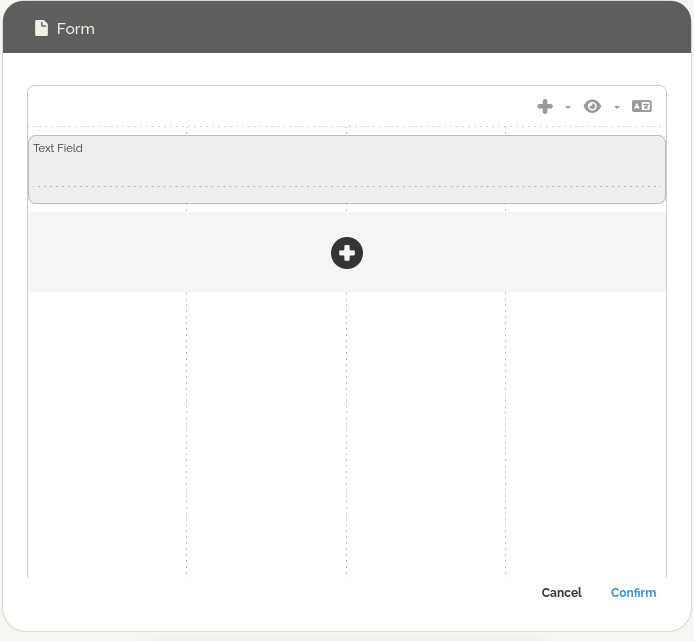
- Ici, nous devons franchir une étape supplémentaire et, pour cela, deux approches sont possibles :
- La première consiste à utiliser l’identifiant du champ pour mapper le champ du formulaire à l’intérieur de l’application ; pour cela :
- Cliquez sur l’icône de crayon sur le côté droit du champ et sélectionnez l’option « Modifier ».
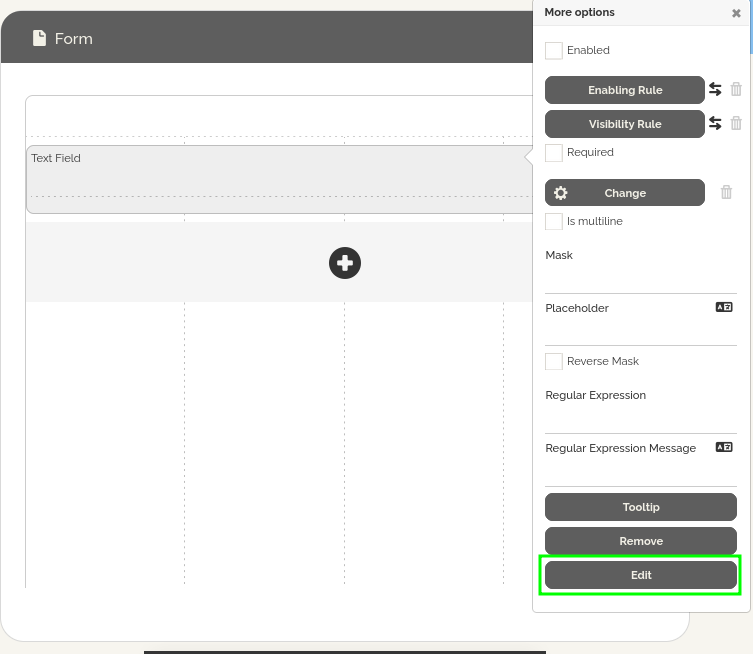
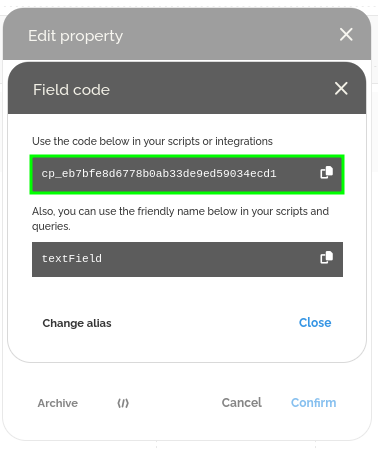
- En bas de la fenêtre, cliquez sur l’icône « </> » pour accéder à l’identifiant du champ et remplacez field_id dans les lignes telles que :
context.WorkItem.Set(« textField »,);
Pour mapper le champ à l’intérieur de l’application.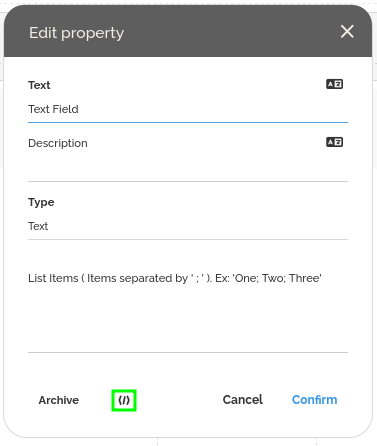
- Cliquez sur l’icône de crayon sur le côté droit du champ et sélectionnez l’option « Modifier ».
- La deuxième consiste à créer un alias personnalisé ; cela permet de garder le code de l’API plus simple et plus facile à maintenir ; pour cela :
- Cliquez sur l’icône de crayon sur le côté droit du champ et sélectionnez l’option « Modifier ».
- En bas de la fenêtre, cliquez sur l’icône « </> » pour accéder à l’identifiant du champ.
- Sélectionnez l’option pour créer un alias et confirmez.
- Utilisez celui-ci à la place de field_id dans les lignes telles que :
context.WorkItem.Set(« textField »,);
Pour mapper le champ à l’intérieur de l’application.En suivant la deuxième approche, créez l’alias suivant pour le champ de texte ; il doit être identique à celui utilisé dans le code.Champ : Champ de Texte Alias : textField ;
- La première consiste à utiliser l’identifiant du champ pour mapper le champ du formulaire à l’intérieur de l’application ; pour cela :
- Il est maintenant temps de configurer l’appel de l’API ; sélectionnez le flux d’exécution entre les deux tâches et, dans l’onglet d’exécution (menu des propriétés), cliquez sur le bouton d’exécution.
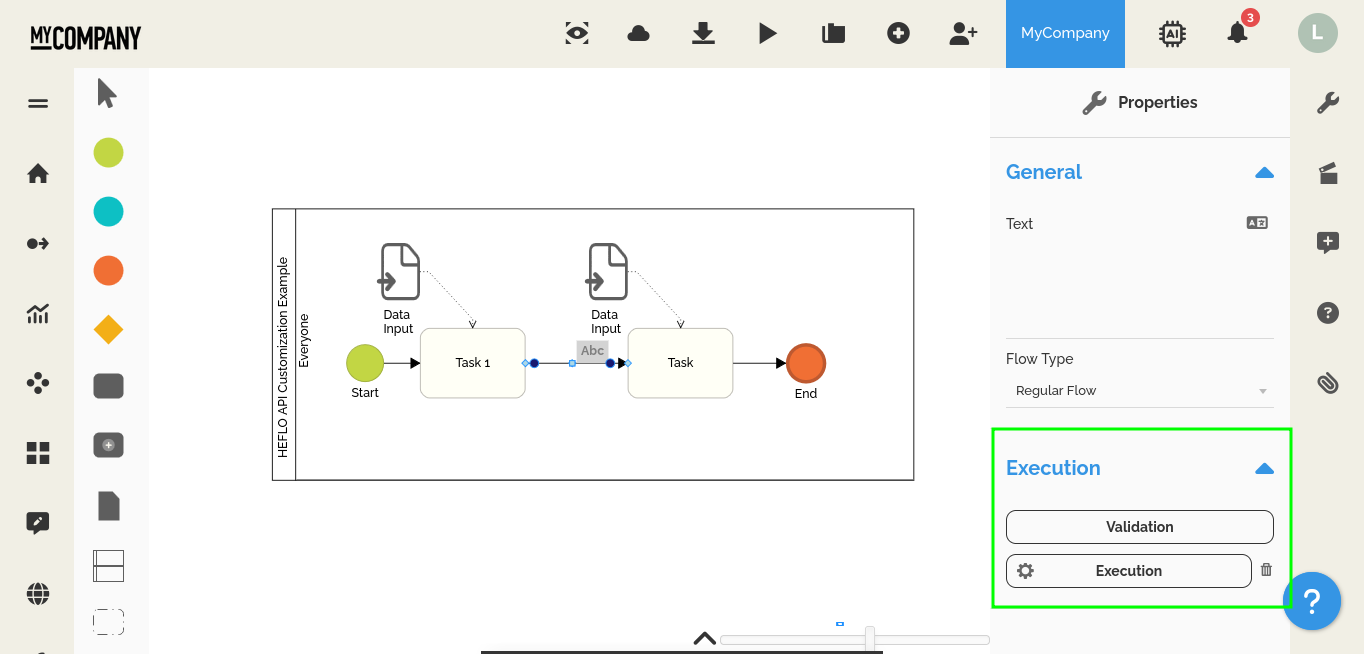
- Dans le type de personnalisation, sélectionnez API en utilisant NodeJS.
- Ici, nous devons configurer l’appel du web service. Pour cet exemple, créez un nouveau web service et définissez :
- URL de Production : https://abcd-1234.ngrok-free.app/
- Ressource : function01
- Méthode : Post
- Authentification : Aucune
Où l’URL de production doit être la même que celle affichée dans le terminal ngrok.
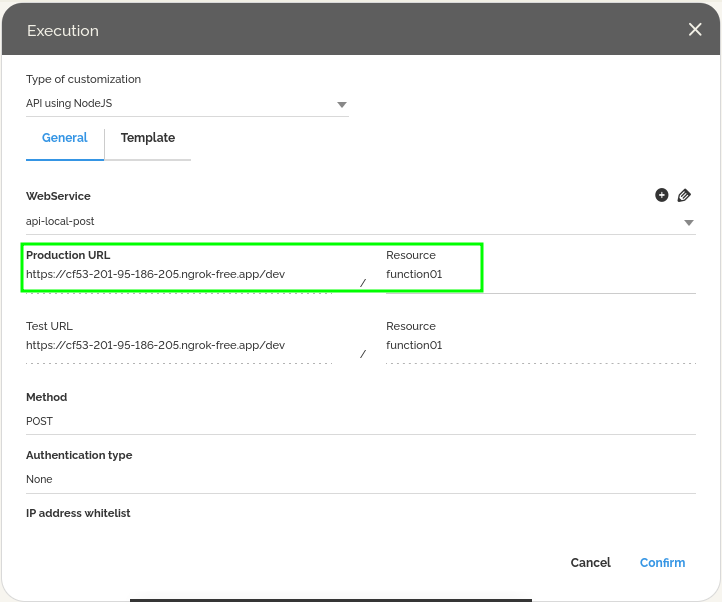
Notez que nous n’avons pas besoin de configurer de paramètres d’envoi et de réponse ; toutes les informations seront manipulées à l’intérieur de l’application et envoyées dans l’environnement HEFLO au sein d’un contexte.
- Confirmez la configuration.
- Sauvegardez la configuration.
- Dans l’éditeur, faites un clic droit sur l’élément de début et sélectionnez « Tests», puis « Démarrer un nouvel élément de travail ».
- Validez la configuration.
Un point intéressant est que ce petit projet peut être adapté davantage pour modéliser des règles métier complexes et servir de point de départ pour de futurs projets. D’autres scénarios d’utilisation courants incluent :
- Les événements de changement de champ ;
- L’initialisation de formulaire ;
- L’exécution de bouton d’action ;
- L’exécution de flux de séquence ;
- Les validations d’approbation ;
- L’attribution dynamique des participants ;
- Les intégrations externes.
Le point de terminaison de personnalisation reçoit le contexte d’exécution du processus de la part de HEFLO et renvoie les données modifiées à la plateforme. Cette approche permet de mettre en œuvre des règles métier avancées tout en préservant la clarté et la maintenabilité du modèle BPMN.
Considérations Finales
Les personnalisations d’API HEFLO offrent une puissante couche d’extension pour les projets d’automatisation de processus. En combinant la modélisation de processus BPMN, la personnalisation en Node.js et le déploiement Serverless, les organisations peuvent mettre en œuvre des solutions d’automatisation hautement flexibles et faciles à maintenir.
La bibliothèque d’API HEFLO simplifie l’interaction avec les processus et permet aux développeurs de se concentrer sur la logique métier plutôt que sur les détails de l’infrastructure.